
Why the best test data sets aren’t a “copy from live”!
It’s an all too common problem that usually goes something like this...



![[Missing text '/pageicons/altmail' for 'English']](/Static/img/email.png)
0330 588 8000
0330 588 8000

+3305888221
+3305888221
Test Engineer: “We need some test data for the next test phase.”
Test Manager: “We haven’t got any – how long will it take to create some?”
Test Engineer: (Frantically doing sums in their head) “2 weeks with two people from the current team.”
Test Manager: “Ok I’ll check with the Programme Manager.”
<meeting between Test Manager and Programme Manager some time later>
Test Manager: “Can we add two elapsed weeks to the overall plan and 20 man-days to the costs to allow for effort to create test data?”
Programme Manager: “Do we have a change request to cover that?”
Test Manager: “No, it’s not a change, we just need to factor in the creation of some test data.”
Programme Manager: “Well if it isn’t a change then it has to be a no – sorry I have to keep to the budget.”
There follows an awkward pause and then there is a flash of inspiration from the Programme Manager.
Programme Manager: “I have a great idea! Why don’t you use a copy of the live data for your test data, there is more data in there than you could ever need! We did this on our last project, all you have to do is anonymise some of the data here and there to remove any personal stuff and then its job done!”
The Programme Manager turns away happy the problem is solved, and his elapsed time and budget are still intact.
But: is it a great idea? Should we ever do this?
I believe that Testing should aim to find defects as soon as possible and avoid un-detected defects being carried forward into subsequent phases.
If we restrict our testing against the live data set then we can inhibit the creation of new or “edge” test cases that require test data that won’t exist in a live dataset but could occur in the future and it is these future possibilities that need to be explored if we are to avoid problems caused that can be categorised as “no one has ever tried that before”. The pure copy of a live data set for testing won’t facilitate this important exercise and tends to limit exploratory testing thinking.
Testing should aim for a minimum amount of test data with as few test cases as possible to cover as wide a variety of scenarios as possible.
Ideally, what we are looking for in a test data set has maximum variety, so that edge test cases can be explored, and minimum volume, to reduce the chance of missing incorrect results.
It is tempting to think that if you run the latest software release against a fresh copy of the live data set and there are no problems then there should be no problems when you go live.
This is faulty thinking: the bigger the test data set is the more likely we are to miss an incorrect actual result.
The bigger the data set the harder it is to manage and the greater resources it consumes which is a cost.
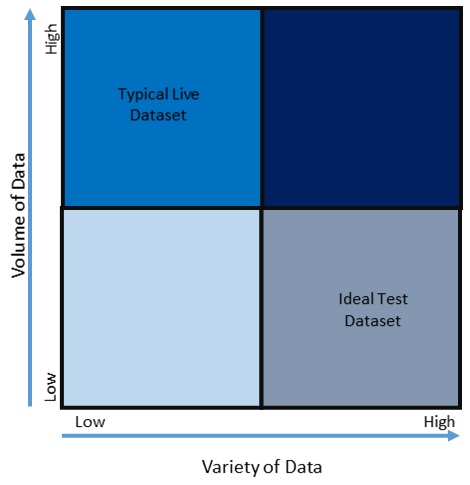 Live datasets tend to be big on volume but short on variety. The majority of data points won’t be at the extremes needed to exercise edge test cases. Live datasets can be characterised as High in Volume but Low in Variety.
Live datasets tend to be big on volume but short on variety. The majority of data points won’t be at the extremes needed to exercise edge test cases. Live datasets can be characterised as High in Volume but Low in Variety.
The ideal test dataset will cover as much variety as possible with a minimum of volume to facilitate the actual results checking process and to provide a platform to explore edge test cases that require “extreme” data points. The Ideal test dataset can be characterised as Low in Volume but High in Variety.
The only upside of utilising a high-volume dataset can be where there is an emphasis on Performance Testing, however the effort required to anonymise any copy of live data may well be outweighed by generating fresh data which can be homogeneous in nature and “fake” without compromising the veracity of Performance Testing which is typically focused on timings and throughput.
So: as a plea to test teams everywhere please resist the temptation, or directive, to use live data as your test data set. If you have a voice at the project planning stage then make sure that the creation of test data is properly planned in and you will reap the quality benefits downstream and de-risk live deployments through the proper exploration of edge test cases and exercising the application paths less trodden.
-
Sogeti UKMake an enquiry
0330 588 8000
Sogeti UKMake an enquiry
0330 588 8000
-
Phil LuptonAccount Director, Sogeti UK
+3305888221
Phil LuptonAccount Director, Sogeti UK
+3305888221